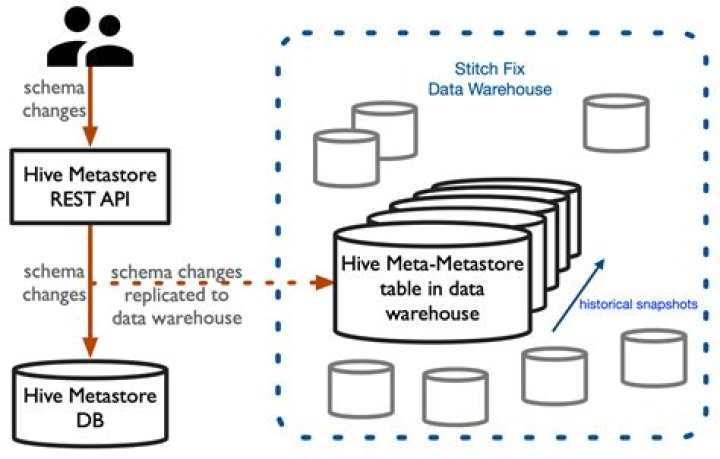
Finally the location of the metastore for hive is by default located here /usr/hive/warehouse .
What is Metastore service?
Hive metastore (HMS) is a service that stores metadata related to Apache Hive and other services, in a backend RDBMS, such as MySQL or PostgreSQL. A separate RDBMS supports the security service, Ranger for example. … All connections are routed to a single RDBMS service at any given time.
What is Hive Metastore tables?
Big SQL and Hive Metastore Introduction The Hive metastore stores the metadata for Hive tables, this metadata includes table definitions, location, storage format, encoding of input files, which files are associated with which table, how many files there are, types of files, column names, data types etc.
What is Metastore in Databricks?
Every Azure Databricks deployment has a central Hive metastore accessible by all clusters to persist table metadata. Instead of using the Azure Databricks Hive metastore, you have the option to use an existing external Hive metastore instance.Why Hive Metastore is Rdbms?
Hive stores metadata information in the metastore using RDBMS instead of HDFS. The reason for choosing RDBMS is to achieve low latency as HDFS read/write operations are time consuming processes. Q) Whenever we run a Hive query, a new metastore_db is created.
How do I find Metastore in Hive?
You can query the metastore schema in your MySQL database. Something like: mysql> select * from TBLS; More details on how to configure a MySQL metastore to store metadata for Hive and verify and see the stored metadata here.
What is Derby in Hive?
Derby is a open source relational database management system. It is developed by Apache Software Foundation in 1997. It is written and implemented completely in the Java programming language. The primary database model of Derby is Relational DBMS. All OS with a Java VM are server operating system.
What is Hive standalone Metastore?
Beginning in Hive 3.0, the Metastore is released as a separate package and can be run without the rest of Hive. This is referred to as standalone mode. By default the Metastore is configured for use with Hive, so a few configuration parameters have to be changed in this configuration.How do I open Metastore in Hive?
Use this command to start HMS: sudo /usr/lib/hive/bin/thrift-metastore server start . Use this command to stop HMS: sudo /usr/lib/hive/bin/thrift-metastore server stop .
What is pool in Databricks?June 29, 2021. Databricks pools reduce cluster start and auto-scaling times by maintaining a set of idle, ready-to-use instances. When a cluster is attached to a pool, cluster nodes are created using the pool’s idle instances.
Article first time published onWhat is hive and its architecture?
Architecture of Hive Hive is a data warehouse infrastructure software that can create interaction between user and HDFS. The user interfaces that Hive supports are Hive Web UI, Hive command line, and Hive HD Insight (In Windows server). Meta Store.
Does Databricks have hive?
Apache Spark SQL in Databricks is designed to be compatible with the Apache Hive, including metastore connectivity, SerDes, and UDFs.
What is spark Metastore?
A Hive metastore warehouse (aka spark-warehouse) is the directory where Spark SQL persists tables whereas a Hive metastore (aka metastore_db) is a relational database to manage the metadata of the persistent relational entities, e.g. databases, tables, columns, partitions.
What is glue Metastore?
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it simple and cost-effective to categorize your data, clean it, enrich it, and move it reliably between various data stores. …
What is Apache iceberg?
Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to compute engines including Spark, Trino, PrestoDB, Flink and Hive using a high-performance table format that works just like a SQL table.
Why Metastore is not stored in HDFS?
A file system like HDFS is not suited since it is optimized for sequential scans and not for random access. So, the metastore uses either a traditional relational database (like MySQL, Oracle) or file system (like local, NFS, AFS) and not HDFS.
Which query language is used in hive?
Hive queries are written in HiveQL, which is a query language similar to SQL. Hive allows you to project structure on largely unstructured data. After you define the structure, you can use HiveQL to query the data without knowledge of Java or MapReduce.
Why Metastore is used in between query processing?
For syntax and semantic analysis or validation for your query, even in the execution engine, it contains the metastore before executing your queries, so all these responses to speed up the processing between these components an RDBMS is used as a metastore here in Hive.
How do I start a hive Derby database?
- Download Derby.
- Set Environment.
- Starting Derby.
- Configure Hive to Use Network Derby.
- Copy Derby Jar Files.
- Start Up Hive.
- The Result.
Is Apache Derby an in memory database?
For testing and developing applications, or for processing transient or reproducible data, you can use Derby’s in-memory database facility. An in-memory database resides completely in main memory, not in the file system.
What is called metadata?
Metadata is defined as the data providing information about one or more aspects of the data; it is used to summarize basic information about data which can make tracking and working with specific data easier. Some examples include: Means of creation of the data.
What is the difference between local and remote Metastore?
In comparison with the Local mode, there is one benefit of using the Remote mode, that is Remote mode does not need the administrator to share JDBC login information for the metastore database along with each Hive user, but local mode does.
What is bucketing in Hive with example?
Bucketing in hive is the concept of breaking data down into ranges, which are known as buckets, to give extra structure to the data so it may be used for more efficient queries. The range for a bucket is determined by the hash value of one or more columns in the dataset (or Hive metastore table).
What is the default Metastore for Hive?
Configuration ParameterDescriptionDefault Valuehive.metastore.portHive metastore listener port. (Hive 1.3.0 and later.)9083
How do I write Hive-site XML Metastore MySQL?
- i. Install MySQL. [php]$sudo apt-get install mysql-server[/php]
- ii. Copy MySQL connector to lib directory. Download MySQL connector (mysql-connector-java-5.1.35-bin.jar) and copy it into the $HIVE_HOME/lib directory. …
- iii. Edit / Create configuration file hive-site. xml.
Where is Hive Metastore URI?
While in the Hive service, click Service Actions > Add Hive Metastore. Select a host and then confirm. Start the Hive service. Metastore clients find the URI of the metastore from the configuration parameter hive.
Does Presto have a Metastore?
Presto is the SQL Engine to plan and execute queries, S3 is the storage service for table partition files, and Hive Metastore is the catalog service for Presto to access table schema and location information.
Is Presto based on Hive?
Presto is designed to comply with ANSI SQL, while Hive uses HiveQL. Presto can handle limited amounts of data, so it’s better to use Hive when generating large reports. … Hive uses map-reduce architecture and writes data to disk while Presto uses HDFS architecture without map-reduce.
Is Presto faster than Hive?
Presto follows the push model, which is a traditional implementation of DBMS, processing a SQL query using multiple stages running concurrently. … If the query consists of multiple stages, Presto can be 100 or more times faster than Hive.
What are clusters in Databricks?
An Azure Databricks cluster is a set of computation resources and configurations on which you run data engineering, data science, and data analytics workloads, such as production ETL pipelines, streaming analytics, ad-hoc analytics, and machine learning.
What is spark pool?
A Spark pool is a set of metadata that defines the compute resource requirements and associated behavior characteristics when a Spark instance is instantiated. These characteristics include but aren’t limited to name, number of nodes, node size, scaling behavior, and time to live.