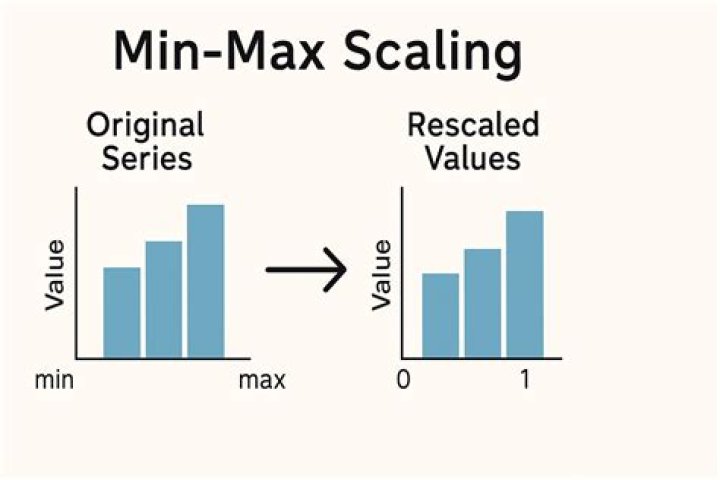
MinMaxScaler. For each value in a feature, MinMaxScaler subtracts the minimum value in the feature and then divides by the range. The range is the difference between the original maximum and original minimum. MinMaxScaler preserves the shape of the original distribution.
What is the use of MinMaxScaler in Python?
Transform features by scaling each feature to a given range. This estimator scales and translates each feature individually such that it is in the given range on the training set, e.g. between zero and one.
What is MinMaxScaler in machine learning?
MinMaxScaler scales all the data features in the range [0, 1] or else in the range [-1, 1] if there are negative values in the dataset. This scaling compresses all the inliers in the narrow range [0, 0.005]. … This method removes the median and scales the data in the range between 1st quartile and 3rd quartile.
Why do we use MinMaxScaler?
MinMaxScaler(feature_range = (0, 1)) will transform each value in the column proportionally within the range [0,1]. Use this as the first scaler choice to transform a feature, as it will preserve the shape of the dataset (no distortion).Which is better MinMaxScaler or StandardScaler?
StandardScaler is useful for the features that follow a Normal distribution. This is clearly illustrated in the image below (source). MinMaxScaler may be used when the upper and lower boundaries are well known from domain knowledge (e.g. pixel intensities that go from 0 to 255 in the RGB color range).
What is scaler fit?
The idea behind StandardScaler is that it will transform your data such that its distribution will have a mean value 0 and standard deviation of 1. In case of multivariate data, this is done feature-wise (in other words independently for each column of the data).
What is MIN-MAX scale?
Also known as min-max scaling or min-max normalization, is the simplest method and consists in rescaling the range of features to scale the range in [0, 1] or [−1, 1]. Selecting the target range depends on the nature of the data.
What is normalization and standardization?
Normalization typically means rescales the values into a range of [0,1]. Standardization typically means rescales data to have a mean of 0 and a standard deviation of 1 (unit variance).How do you rescale data in Python?
- Step 1 – Importing Library. from sklearn import preprocessing import numpy as np. …
- Step 2 – Creating array. We have created a array with values on which we will perform operation. …
- Step 3 – Scaling the array.
- Fit the scaler using available training data. For normalization, this means the training data will be used to estimate the minimum and maximum observable values. …
- Apply the scale to training data. …
- Apply the scale to data going forward.
Why do we use StandardScaler?
StandardScaler removes the mean and scales each feature/variable to unit variance. This operation is performed feature-wise in an independent way. StandardScaler can be influenced by outliers (if they exist in the dataset) since it involves the estimation of the empirical mean and standard deviation of each feature.
What is Sklearn preprocessing in Python?
The sklearn. preprocessing package provides several common utility functions and transformer classes to change raw feature vectors into a representation that is more suitable for the downstream estimators. In general, learning algorithms benefit from standardization of the data set.
How do you normalize data using MinMaxScaler?
- Step 1: fit the scaler on the TRAINING data.
- Step 2: use the scaler to transform the TRAINING data.
- Step 3: use the transformed training data to fit the predictive model.
- Step 4: use the scaler to transform the TEST data.
- Step 5: predict using the trained model (step 3) and the transformed TEST data (step 4).
How do you use StandardScaler?
- Import the necessary libraries required. …
- Load the dataset. …
- Set an object to the StandardScaler() function.
- Segregate the independent and the target variables as shown above.
- Apply the function onto the dataset using the fit_transform() function.
What is StandardScaler in machine learning?
In Machine Learning, StandardScaler is used to resize the distribution of values so that the mean of the observed values is 0 and the standard deviation is 1.
Does scaling treat outliers?
StandardScaler removes the mean and scales the data to unit variance. … However, the outliers have an influence when computing the empirical mean and standard deviation.
What is Normalisation?
What Does Normalization Mean? Normalization is the process of reorganizing data in a database so that it meets two basic requirements: There is no redundancy of data, all data is stored in only one place. Data dependencies are logical,all related data items are stored together.
What is Z scaling?
Z-score is a variation of scaling that represents the number of standard deviations away from the mean. You would use z-score to ensure your feature distributions have mean = 0 and std = 1. It’s useful when there are a few outliers, but not so extreme that you need clipping.
What is feature scaling in Python?
Feature Scaling or Standardization: It is a step of Data Pre Processing that is applied to independent variables or features of data. It basically helps to normalize the data within a particular range. Sometimes, it also helps in speeding up the calculations in an algorithm. Package Used: sklearn.preprocessing.
What is difference between fit () Transform () and Fit_transform ()?
The fit() function calculates the values of these parameters. The transform function applies the values of the parameters on the actual data and gives the normalized value. The fit_transform() function performs both in the same step. Note that the same value is got whether we perform in 2 steps or in a single step.
Should I scale target variable?
Yes, you do need to scale the target variable. I will quote this reference: A target variable with a large spread of values, in turn, may result in large error gradient values causing weight values to change dramatically, making the learning process unstable.
How do I rescale a Numpy array?
Use numpy. abs() and numpy. abs(x) to convert the elements of array x to their absolute values. Use numpy. amax(a) with this result to calculate the maximum value in a . Divide a number x by the maximum value and multiply by the original array to scale the elements of the original array to be between -x and x .
How do you preprocess data in Python?
- from google.colab import drive drive. …
- import numpy as np import matplotlib.pyplot as plt import pandas as pd.
- Dataset = pd. …
- print(x) # returns an array of features.
Why is scaling important in machine learning?
Feature scaling is essential for machine learning algorithms that calculate distances between data. … Since the range of values of raw data varies widely, in some machine learning algorithms, objective functions do not work correctly without normalization.
What is normalization in Python?
Normalization refers to rescaling real-valued numeric attributes into a 0 to 1 range. … Normalization makes the features more consistent with each other, which allows the model to predict outputs more accurately.
What is standardization in Python?
Standardization refers to shifting the distribution of each attribute to have a mean of zero and a standard deviation of one (unit variance). It is useful to standardize attributes for a model that relies on the distribution of attributes such as Gaussian processes.
What is standardization data?
Data standardization is the critical process of bringing data into a common format that allows for collaborative research, large-scale analytics, and sharing of sophisticated tools and methodologies.
Why is scaling important?
Why is scaling important? Scaling, which is not as painful as it sounds, is a way to maintain a cleaner mouth and prevent future plaque build-up. Though it’s not anyone’s favorite past-time to go to the dentist to have this procedure performed, it will help you maintain a healthy mouth for longer.
What is scale data?
Scales of measurement in research and statistics are the different ways in which variables are defined and grouped into different categories. Sometimes called the level of measurement, it describes the nature of the values assigned to the variables in a data set.
Why do we scale variables?
Variables that are measured at different scales do not contribute equally to the analysis and might end up creating a bais. … Using these variables without standardization will give the variable with the larger range weight of 1000 in the analysis. Transforming the data to comparable scales can prevent this problem.
What is a StandardScaler?
StandardScaler standardizes a feature by subtracting the mean and then scaling to unit variance. Unit variance means dividing all the values by the standard deviation. … StandardScaler makes the mean of the distribution 0. About 68% of the values will lie be between -1 and 1.