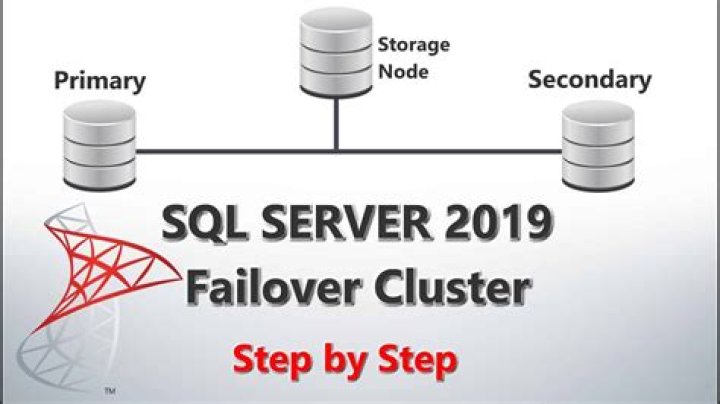
SQL Server failover clusters are made of group of servers that run cluster enabled applications in a special way to minimize downtime. A failover is a process that happens if one node crashes, or becomes unavailable and the other one takes over and restarts the application automatically without human intervention.
How does SQL failover cluster work?
Translation: A failover cluster basically gives you the ability to have all the data for a SQL Server instance installed in something like a share that can be accessed from different servers. It will always have the same instance name, SQL Agent jobs, Linked Servers and Logins wherever you bring it up.
What is a SQL Server cluster?
SQL Server clustering is the term used to describe a collection of two or more physical servers (nodes), connected via a LAN, each of which host a SQL server instance and have the same access to shared storage. … To improve performance, you need to upgrade the computing power of the servers.
What is the purpose of a failover cluster?
A failover cluster is a group of independent computers that work together to increase the availability and scalability of clustered roles (formerly called clustered applications and services).What is the difference between Windows cluster and SQL cluster?
Windows clusters do provide the infrastructure that supports HA for hosted applications which are configured with SQL Server. SQL server uses this feature to configure and support failover.
How do I move a SQL cluster in failover?
Use Failover Cluster Manager > Roles > SQL Server role (1) On Action tab, select “Move” (2) and select the node to move the role to (3) Observe that all resources that SQL Server role depend upon are moved to another node and SQL Server role is now running on new node as well (4).
How do I failover a SQL Server cluster?
- In Object Explorer, connect to a server instance that hosts a secondary replica of the availability group that needs to be failed over. …
- Expand the AlwaysOn High Availability node and the Availability Groups node.
- Right-click the availability group to be failed over, and select Failover.
What is the difference between failover and high availability?
3 Answers. Failover is a means of achieving high availability (HA). Think of HA as a feature and failover as one possible implementation of that feature. Failover is not always the only consideration when achieving HA.What happens to end users when there is a cluster failover?
In a failover cluster, the failover process is triggered if one of the servers goes down. … CA clusters, also called fault tolerant (FT) clusters, eliminate downtime when a primary system fails, allowing end users to keep using services and applications without any timeouts.
What is the difference between failover and failback?The failover operation is the process of switching production to a backup facility (normally your recovery site). A failback operation is the process of returning production to its original location after a disaster or a scheduled maintenance period.
Article first time published onWhat is failover in database?
A failover is when the primary database (all instances of a RAC primary database) fails and one of the standby databases is transitioned to take over the primary role.
What is cluster in SQL with example?
A cluster is a schema object that contains data from one or more tables, all of which have one or more columns in common. Oracle Database stores together all the rows from all the tables that share the same cluster key.
What does enable SQL Server failover support?
Enable SQL Server Failover support. If checked, when a node in the SQL Server failover group isn’t available, Power Query moves from that node to another when failover occurs. If cleared, no failover will occur.
What is the difference between clustering and AlwaysOn?
An SQL AlwaysOn failover cluster instance provides high availability and disaster recovery at the SQL Server level. AlwaysOn Availability Groups (AAG) provide high availability and disaster recovery at SQL database level. … An AlwaysOn node manages backups of availability databases.
Can we configure always on without cluster?
Step 1: We need to enable SQL Always On feature on both standalone SQL instances. To do so, RDP to each server and Open SQL Server Configuration Manager. In this go to SQL Server instance properties and Enable Always On Availability Groups. … We can enable it in SQL Server 2017 or above without failover cluster.
What is always on SQL cluster?
SQL Server Always On is a flexible design solution to provide high availability (HA) and disaster recovery (DR). It is built upon the Windows Failover Cluster, but we do not require the shared storage between the failover cluster nodes. … We define availability groups as a single unit of failure to the secondary replica.
How do you failover a SQL database?
- Connect to the principal server instance and, in the Object Explorer pane, click the server name to expand the server tree.
- Expand Databases, and select the database to be failed over.
- Right-click the database, select Tasks, and then click Mirror. …
- Click Failover.
How do I test a failover cluster in SQL?
- Expand Roles and select SQL Server (MSSQLSERVER).
- Right-click the SQL Server (MSSQLSERVER) role, select Move and click Select Node.
- In the Move Clustered Role dialog box, select the node where you want the SQL Server FCI to move into.
How do you know when a failover occurs in cluster?
The time of the failover will be the same as that of the starting of the new log file. The only way to find whether it was a restart\failover from Error log is to look for this message in the current log, “The NETBIOS name of the local node that is running the server is ‘XXXXXXXXXX’.
How do I make a failover server?
- Click Start > Windows Administrative tools > Failover Cluster Manager to launch the Failover Cluster Manager.
- Click Create Cluster. …
- Click Next. …
- Enter the server names that you want to add to the cluster. …
- Click Add.
- Click Next. …
- Select Yes to allow verification of the cluster services.
Where is failover cluster manager located?
On the server computer, click Start > Administrative Tools > Failover Cluster Manager. The Failover Cluster Manager dialog box appears.
How do I find cluster nodes in SQL Server?
Identify Nodes of SQL Server Failover Cluster using TSQL Query. You can identify the nodes of SQL Server Failover cluster either by using an inbuilt function or using a DMV. Below mentioned queries will return the same result.
What is the difference between failover and load balancing?
Failover and load balancing are vital for Oracle Access Manager availability and performance. Load balancing distributes request processing across multiple servers. Failover redirects requests to alternate servers if the originally requested server is unavailable or too slow.
What is the difference between failover and redundancy?
Failover is having redundancy built into the environment, so that if a server fails, another server takes its place. … Another failover method is to have additional hardware that is being used as a backup for this purpose but is not being used while the primary server is up and running (active/passive approach).
What is roles in failover cluster manager?
Each highly available virtual machine is considered a role in Failover Clustering terminology. A role includes the protected item itself as well as a set of resources used by Failover Clustering for configuration and state data about the protected item.
What is HA mode?
High Availability (HA) describes systems that are dependable enough to operate continuously without failing. They are well-tested and sometimes equipped with redundant components.
What is the difference between HA and redundancy?
High availability means that the systems will always be available regardless of what happens. With redundancy, you may have to flip a switch to move from one server to the other, or you may have to power up a new system to be able to have that system available.
What is difference between HA and DR?
High Availability (HA) provides a failover solution in the event a Control Room service, server, or database fails. Disaster Recovery (DR) provides a recovery solution across a geographically separated distance in the event of a disaster that causes an entire data center to fail.
What is RTO and RPO in disaster recovery?
The shorter the RTO, the greater the resources required. RPO is used for determining the frequency of data backup to recover the needed data in case of a disaster.
What is failover testing?
Failover testing is a technique that validates if a system can allocate extra resources and backup all the information and operations when a system fails abruptly due to some reason. This test determines the ability of a system to handle critical failures and handle extra servers.
What is DR failover testing?
What Is Disaster Recovery Testing? Disaster recovery testing involves simulating an IT failure or any other type of business disruption to assess a DR plan. The main objective of disaster testing is to check if an organization can restore operations within the planned time.