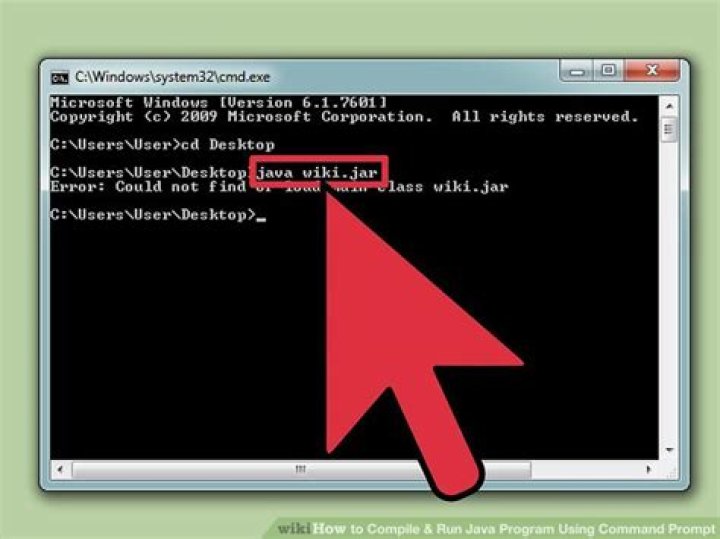
Apache Avro Avro stores the data definition (schema) in JSON format making it easy to read and interpret by any program. The data itself is stored in binary format making it compact and efficient.
How do you make an Avro schema?
- Create a SensorData.avsc file and save it in the avro subdirectory of the example project. …
- Create a Measurements.avsc file and save it in the avro subdirectory of the example project. …
- Create a Metric.avsc file and save it in the avro subdirectory of the example project.
What is record type in Avro schema?
A record data type in Avro is a collection of multiple attributes. It supports the following attributes − name − The value of this field holds the name of the record. namespace − The value of this field holds the name of the namespace where the object is stored.
What is the use of Avro schema in Kafka?
In the Kafka world, Apache Avro is by far the most used serialization protocol. Avro is a data serialization system. Combined with Kafka, it provides schema-based, robust, and fast binary serialization.Is Avro better than JSON?
We think Avro is the best choice for a number of reasons: It has a direct mapping to and from JSON. It has a very compact format. The bulk of JSON, repeating every field name with every single record, is what makes JSON inefficient for high-volume usage.
What is Avro schema example?
Avro was the default supported format for Confluent Platform. For example, an Avro schema defines the data structure in a JSON format. The following Avro schema specifies a user record with two fields: name and favorite_number of type string and int , respectively.
Does order matter in Avro schema?
Avro serializer/deserializers operate on fields in the order they are declared. Producers and Consumers must be on a compatible schema including the field order. Do not change the order of AVRO fields. … A record is encoded by encoding the values of its fields in the order that they are declared.
Why is Avro used?
While we need to store the large set of data on disk, we use Avro, since it helps to conserve space. Moreover, we get a better remote data transfer throughput using Avro for RPC, since Avro produces a smaller binary output compared to java serialization.What do you mean by schema?
A schema is a cognitive framework or concept that helps organize and interpret information. Schemas can be useful because they allow us to take shortcuts in interpreting the vast amount of information that is available in our environment.
Why we need schema registry in Kafka?Schema Registry acts as a service layer for metadata. It stores a versioned history of all the schema of registered data streams and schema change history. … Instead of appending the whole schema info, only schema ID needs to be set with each set of records by the producer while sending messages to Kafka’s topic.
Article first time published onWhat is Avro in big data?
Avro is an open source project that provides data serialization and data exchange services for Apache Hadoop. These services can be used together or independently. Avro facilitates the exchange of big data between programs written in any language. … The data storage is compact and efficient.
Is Avro better than Protobuf?
Avro is the most compact but protobuf is just 4% bigger. Thrift is no longer an outlier for the file size in the binary formats. All implementations of protobuf have similar sizes. XML is still the most verbose so the file size is comparatively the biggest.
Is Avro smaller than JSON?
JSON vs AVRO In their uncompressed form JSON that is a text based format is larger than AVRO that is a binary based format. AVRO occupies just quater JSON for trip data that is a time series dataset and just 40% of JSON for wikimedia that is a semi structured dataset. AVRO is very compact and fast.
Should I use Avro with Kafka?
Yes. You could use Apache Avro. Avro is a data serialization format that is developed under the Apache umbrella and is suggested to be used for Kafka messages by the creators of Apache Kafka themselves.
Is Avro human readable?
ORC, Parquet, and Avro are also machine-readable binary formats, which is to say that the files look like gibberish to humans. If you need a human-readable format like JSON or XML, then you should probably re-consider why you’re using Hadoop in the first place.
Does Avro support timestamp?
Avro has logical type timestamp and hive supports it since this patch
What is Avro medium?
medium.com. Apache Avro: Avro is a data serialization system, it provides a compact binary data format to serialize data. Avro depends on Schema which we can define using Json format.
What is schema and its types?
Schema is of three types: Logical Schema, Physical Schema and view Schema. Logical Schema – It describes the database designed at logical level. Physical Schema – It describes the database designed at physical level. View Schema – It defines the design of the database at the view level.
What does schema mean in reading?
SCHEMA: Schema is a reader’s background knowledge. It is all the information a person knows – the people you know, the places you have been, the experiences you have had, the books you have read – all of this is your schema. Readers use their schema or background knowledge to understand what they are reading.
What is schema in PostgreSQL?
A PostgreSQL database cluster contains one or more named databases. Schemas also contain other kinds of named objects, including data types, functions, and operators. … The same object name can be used in different schemas without conflict; for example, both schema1 and myschema can contain tables named mytable.
How does Avro look like?
AVRO File Format Avro format is a row-based storage format for Hadoop, which is widely used as a serialization platform. Avro format stores the schema in JSON format, making it easy to read and interpret by any program. The data itself is stored in a binary format making it compact and efficient in Avro files.
Is schema registry part of Apache Kafka?
Basically, for both Kafka Producers and Kafka Consumers, Schema Registry in Kafka stores Avro Schemas. It offers a RESTful interface for managing Avro schemas. It permits for the storage of a history of schemas that are versioned. Moreover, it supports checking schema compatibility for Kafka.
What is a schema registry in Kafka?
Schema Registry provides a serving layer for your metadata. It provides a RESTful interface for storing and retrieving Avro schemas. It provides serializers that plug into Kafka clients that handle schema storage and retrieval for Kafka messages that are sent in the Avro format. …
Do I need schema registry?
Why we need Schema Registry? Schema registry allows producers and consumers to update independently and evolve their schemas independently, with assurances that they can read new and old data.
Where are Avro schema stored?
AvroSerDe’ STORED AS INPUTFORMAT ‘org. apache. hadoop.
How does schema evolve?
Schema evolution is a feature that allows users to easily change a table’s current schema to accommodate data that is changing over time. Most commonly, it’s used when performing an append or overwrite operation, to automatically adapt the schema to include one or more new columns.
What is the difference between Avro and JSON?
It is based on a subset of the JavaScript Programming Language. Avro can be classified as a tool in the “Serialization Frameworks” category, while JSON is grouped under “Languages”. Redsift, OTTLabs, and Mon Style are some of the popular companies that use JSON, whereas Avro is used by Liferay, LendUp, and BetterCloud.
What does a serializer do?
According to Microsoft documentation: Serialization is the process of converting an object into a stream of bytes to store the object or transmit it to memory, a database or file. Its main purpose is to save the state of an object in order to be able to recreate it when needed.
Is Protobuf faster than Avro?
According to JMH, Protobuf can serialize some data 4.7 million times in a second where as Avro can only do 800k per second. The test data that was serialized is around 200 bytes and I generated schema for both Avro and Protobuf.
Which data format is faster?
rjson. rjson is the fastest JSON implementation – only 10 times slower than msgpack , in memory, and 2.7 times slower across the wire.
Why parquet is best for spark?
1- Columnar storage limits IO operations. 2- Columnar storage can fetch specific columns that you need to access. 3-Columnar storage consumes less space. 4- Columnar storage gives better-summarized data and follows type-specific encoding.